import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.api as sm
import pymc as pm
import arviz as az
import bambi as bmb
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
# Turn off logging (console output) for PyMC
import logging
logging.getLogger("pymc").setLevel(logging.ERROR)
sns.set()(Almost) every dataset we work with has some amount of uncertainty in it. Everything from the randomness in a sample, measurement error, differences between the data and the underlying truth they represent, and much more can lead to uncertainty.
Therefore, anything we compute using the data also inherits some uncertainty. So, it’s important to always report that uncertainty:
If we infer a parameter or trend, we should report our uncertainty in the inference.
If we make a prediction, we should report our uncertainty in the prediction.
If we draw a conclusion, we should report our uncertainty in the conclusion.
While uncertainty quantification looks slightly different from frequentist and Bayesian perspectives, the core ideas above remain true regardless.
Frequentist Uncertainty Quantification¶
In the frequentist setting, we treat our data as random, but our unknowns as fixed. So, any uncertainty we quantify is only over the data! We cannot make statements like “The unknown is probably within” or “The probability of the parameter being..”.
While these statements can be more intuitive and might align with what we want to say when quantifying uncertainty, they only make sense in the context of a probability model for the unknown: we’ll have to take a Bayesian approach in order to say anything of this sort.
The main way we’ll quantify uncertainty in the frequentist setting is by using the distribution of our estimators. Specifically, whenever we estimate some parameter with an estimator , the estimator is random, because it depends on the random data (even if is fixed). So, we can use the distribution of to quantify uncertainty.
We already know that if we have the distribution of , we can construct a confidence interval, which gives us an idea of how much our estimator could vary if we had observed different datasets. But before we can construct one, we need to determine the distribution for .
UQ with the Central Limit Theorem¶
For more on the Central Limit Theorem, see Chapter 14 of the Data 140 textbook.
If we want to use the distribution of to quantify our uncertainty, then we have to start by answering: "what is the distribution of ?
In the case where is the sample mean, we can answer this with one of the most beautiful results in statistics: the Central Limit Theorem. Briefly, this states that if is the sample mean of data points , where each has mean and (finite) variance , then the distribution of converges to a normal distribution with mean and variance .
Note that a similar result holds for any maximum likelihood estimate! While the details are beyond the scope of this class, one can show that if is the maximum likelihood estimate for some parameter based on data points , then the distribution for also converges to a normal distribution, with mean and variance . Here, is the Fisher informatoin of the likelihood, which quantifies how much information each gives us about .
While the details (e.g., Fisher information) are beyond the scope of this class, the takeaway is important:
Asymptotically (i.e., as the number of observations gets very large), the distribution of a maximum likelihood estimator, like that of a sample mean, converges to a normal distribution.
UQ with the Bootstrap¶
You may find it helpful to review Chapter 13.2 of the Data 8 textbook, which covers the bootstrap.
In many cases, we might not be able to compute the distribution of analytically. In some of these cases, we can use the bootstrap to quantify uncertainty.
Bootstrap limitations¶
The bootstrap works well in most, but not all situations. Here are some guidelines for when to (and when not to) use it:
The bootstrap is a good choice when the presence or absence of a single sample won’t change the estimate dramatically (e.g., this is not true for the min or max)
The bootstrap is a good choice when the number of data points is very small
The bootstrap is a good choice when the number of parameters being estimated is much smaller than the number of data points (e.g., this is not true for neural networks, where we are estimating a very large number of parameters)
Confidence intervals¶
You may find it helpful to review Section 13.3 of the Data 8 textbook, which covers confidence intervals.
A confidence interval provides a measure of uncertainty about our estimator, based on its distribution. Recall that confidence intervals provide a guarantee about the process, not about the location of the (fixed) unknown parameter. Specifically, thinking about a 95% confidence interval, we know that 95% of datasets will produce an interval that contains the true parameter. We don’t know whether our interval happens to be one of the lucky 95%, or one of the unlucky 5%.
Uncertainty in GLMs: comparing coefficient and prediction intervals¶
When quantifying uncertainty in GLMs, it’s important to keep in mind that there are multiple sources of uncertainty. For example, consider our estimate of the coefficients, , computed from data . These are computed as the maximum likelihood estimates given the observed data, and so have inherent uncertainty in them. In other words, if we had observed a different dataset, we might have gotten a different set of estimated coefficients .
Now, consider our estimated prediction for a new data point, . To simplify, we’ll focus on linear regression with a scalar . In this case, we can write the distribution for the new value as:
Here, there are two sources of uncertainty: (1) the uncertainty in our estimator for the coefficients, ; and (2) the uncertainty in the observed value and how far away it’ll be from the average prediction (i.e., prediction line), as quantified by .
So, if we want to construct a confidence interval for , we need only consider the first source of uncertainty. But, if we want to construct a confidence interval for , we need to consider both sources of uncertainty! This second type of interval is often called a prediction interval.
Bayesian Uncertainty Quantification¶
In the Bayesian setting, we treat our unknown parameters as random. This means that we can make statements like “The unknown is probably between A and B”, which we couldn’t in the frequentist setting.
Credible Intervals¶
This motivates the definition of a credible interval. A credible interval for a parameter , , says that there is a chance that, given the observed data, the parameter falls between and . For example, suppose we produce a credible interval for of . This tells us that given our observed data, the probability of being between 0.3 and 1.7 is 0.9, or equivalently (assuming is continuous).
Notice how much simpler this definition is than the confidence interval! This is one of the advantages of taking a Bayesian approach: treating our unknown as random lets us make intuitive statements about the probability that it takes on certain values.
However, one problem with this definition is that it is not unique! Indeed, there are many possible credible intervals for a given level of confidence/credibility. Consider the following distribution, and the three possible credible intervals. For all three, the total shaded blue area is , so all three are valid credible intervals. Which one would you prefer?
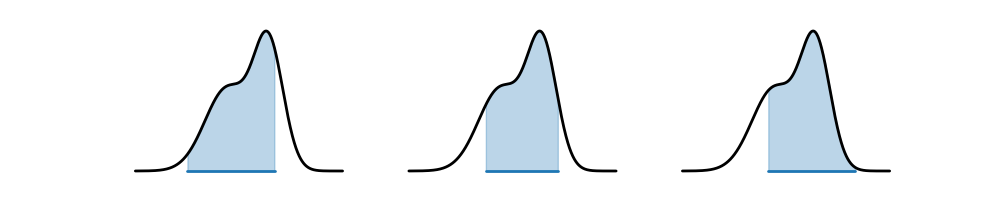
The one in the center seems the most appealing: it covers an area of highest density, and is also the narrowest. This motivates the definition of a highest density interval (HDI), sometimes also called a highest posterior density (HPD) interval. The HDI is the narrowest interval for a given level of credibility/confidence.
Exercise: is the HDI always unique? If not, then what constraints could we place on the posterior to ensure it’s unique?
We can see that the intervals we saw in Section 3.3 were HDIs that PyMC automatically constructed for us.
Constructing HDIs from samples¶
Given a posterior in closed form, we could analytically find and to minimize the width of the interval. But in practice, we rarely obtain posterior distributions in closed form: we usually end up approximating them with samples. So, how might we find an HDI with samples?
Let’s do a simple example with some samples from a Beta-distributed random variable:
num_samples = 200
distribution = stats.beta(3, 4)
samples = distribution.rvs(num_samples)
samples[:5]array([0.37568015, 0.3054924 , 0.40978748, 0.10349559, 0.17014057])Call the samples . We can construct a credible interval by sorting the samples, choosing any and so that , and reporting :
sorted_samples = np.sort(samples)
(i1, j1) = (10, 190)
(i2, j2) = (15, 195)
credible_interval_1 = (sorted_samples[i1], sorted_samples[j1])
credible_interval_2 = (sorted_samples[i2], sorted_samples[j2])
print(credible_interval_1)
print(credible_interval_2)(0.12893626829279511, 0.7639256588702239)
(0.16097668346313884, 0.8235097328985005)
How can we find the HDI? We can simply search over all intervals of width , and find the narrowest one.
credibility = 0.9
narrowest_start_so_far = -1
narrowest_width_so_far = np.inf
interval_samples = int(num_samples * credibility)
for start in range(20): # Make sure you understand why we can stop at 20!
end = start + interval_samples
width = sorted_samples[end] - sorted_samples[start]
if width < narrowest_width_so_far:
narrowest_start_so_far = start
narrowest_width_so_far = width
print((
sorted_samples[narrowest_start_so_far],
sorted_samples[narrowest_start_so_far + interval_samples]
))(0.1028881402605869, 0.7219133542569751)
Bayesian UQ for Predictions¶
Just as in the frequentist world, in Bayesian GLMs, we can also construct credible intervals for our predictions! These will be constructed using the posterior predictive density, and inherit the uncertainty in the inference for the unknown coefficients as well as the uncertainty in the inference for parameters like in linear regression.