import numpy as np
import pandas as pd
from scipy import stats
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()Graphical Models, Probability Distributions, and Independence¶
Graphical Models¶
A graphical model provides a visual representation of a Bayesian hierarchical model using. These models are sometimes known as Bayesian networks, or Bayes nets.
We represent each random variable with a node (circle), and a directed edge (arrow) between two random variables indicates that the the distribution for the child variable is conditioned on the parent variable. When drawing graphical models, we usually start with the variables that don’t depend on any others. These are usually, but not always, unobserved parameters of interest like in this example. Then, we proceed by drawing a node for each variable that depends on those, and so on. Variables that are observed are shaded in.
We’ll draw graphical models for the three examples we’ve seen in previous sections: the product review model, the kidney cancer model, and the exoplanet model.
Graphical model for product reviews¶
In our product review model, we have the following random variables:
In this case, this means we start with a node for the product quality , and then with one node for each review , all of which depend on . The nodes for the observed reviews are shaded in, while the node for the hidden (unobserved) product quality is not:
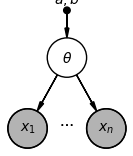
This visual representation shows us the structure of the model, by making it clear that each review depends on the quality . But just as before, this model is simple enough that we already knew that. Next, we’ll look at the graphical model for a more interesting example.
Graphical model for kidney cancer death risk¶
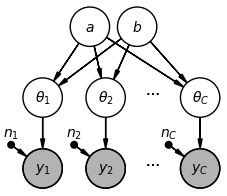
Recall the full hierarchical model for the kidney cancer death risk example:
represents the number of kidney cancer deaths in county (out of a population of ).
represents the kidney cancer death rate for county .
and represent the parameters of the shared prior for the county-level rates.
In order to draw the graphical model, we need to draw one node per random variable, and draw arrows to indicate dependency. We know that:
We need a node for and a node for .
We need one node for each and one node for each .
Each depends on and .
Each depends on and .
Because is a fixed number, we’ll draw it as a dot.
So, our full graphical model looks like:
Relating graphical models to probability distributions¶
When we were drawing graphical models above, we drew one node per variable, and started from the “top,” working with the variables that didn’t depend on any others. We then worked our way through the model, ending with observed variables. When looking at a graphical model to derive the corresponding joint distribution of all the variables in the model, we follow a similar process. For example, in the kidney cancer death rate model, we can write the joint distribution of all the variables in our model by starting at the root (i.e., the nodes that have no parents), and then proceeding through their children, writing the joint distribution as a product.
So, we start with and , then (for ), then :
Factoring the distribution this way helps us understand and mathematically demonstrate the independence and dependence relationships in our graphical models, as we’ll see shortly.
Independence and Conditional Independence¶
Review: independence and conditional independence¶
We say that two random variables and are independent if knowing the value of one tells us nothing about the distribution of the other. Notationally, we write . The following statements are all true for independent random variables and :
If and are independent (), then the joint distribution can be written as the product of the marginal distributions: .
If and are independent (), then the conditional distributions are equal to the marginal distributions: and .
Exercise: using the definition of conditional distributions, show that the two conditions above are mathematically equivalent.
We say that two random variables and are conditionally independent given a third random variable if, when we condition on , knowing the value of one of or tells us nothing about the distribution of the other. Notationally, we write , and mathematically this means that .
For example, suppose and are the heights of two people randomly sampled from a very specific population with some average height : this population could be college students, or second-graders, or Olympic swimmers, or some other group entirely.
If we know the value of , then and are conditionally independent, because they’re random samples from the same distribution with known mean . For example, if we are given that , then knowing does not tell us anything about .
Suppose instead that we don’t know the value of . Then, we find out that . In this case, we might guess that the ‘specific population’ is likely a very tall group, such as NBA players. This will affect our belief about the distribution of (i.e., we should expect the second person to be tall too). So, in this case:
and are conditionally independent given : .
and are not unconditionally independent: it is not true that .
Independence and conditional independence in graphical models¶
The structure of a graphical model can tell us a lot about the independence relationships between the variables in our model. Specifically, we can determine whether two random variables are unconditionally independent or conditionally independent given a third variable, just by looking at the structure of the model. Let’s look at a few examples to illustrate this. We’ll start with the height example we just saw:
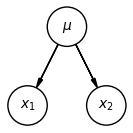
From our reasoning above, we know that , but that and are not unconditionally independent. This is true in general for any three variables in a graphical model in this configuration.
Exercise: mathematically prove the results stated above.
Solution: To show that and are not unconditionally independent, we must show that . We can compute by looking at the joint distribution over all three variables and then marginalizing over :
Unfortunately, there is no way to factor the integral that separates terms with and terms with , so this does not factor. In other words, in general, the integral above will not equal , so the variables are not unconditionally independent.
What about conditional independence given ? We need to show that :
This mathematical result aligns with the intuition we built in the previous section.
Let’s look at another example:
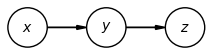
In this example, and are not unconditionally independent. Intuitively, we can see that depends on , and depends on , so that and are dependent.
But, and are conditionally independent given : the lack of an arrow directly from to tells us that only depends on through .
Exercise: mathematically prove the results stated above.
Let’s look at a third example:
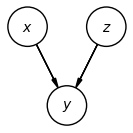
In this example, and are unconditionally independent, but given , they are conditionally dependent. Why? Let’s look at an example that will help us build intuition for this result. Suppose that:
is whether or not I have a stuffy nose.
is whether or not I am sick (with a cold, flu, COVID, etc.)
is whether or not I have seasonal allergies.
First, we can see that the description matches the graphical model: whether or not I have a stuffy nose depends on whether or not I’m sick, and whether or not I have allergies. But, sickness and allergies don’t affect each other. In other words, if I don’t know anything about whether I have a stuffy nose, then my sickness and allergies are independent of each other.
Now, suppose I wake up one morning with a stuffy nose (i.e., ), and I’m trying to determine whether I’m sick or have allergies. I look at the weather forecast, and see that the pollen counts are very high. As soon as I hear this information, I’m a lot more certain that . But, even though the weather forecast didn’t directly tell me anything about whether or not I’m sick, my belief that I’m sick drops significantly: my symptoms have been explained away by the explanation that I probably have allergies.
In other words, conditioned on a value of (stuffy nose), knowing something about (allergies) gives me information about the distribution of (sickness). This is precisely the definition of conditional dependence.
Exercise: mathematically prove the results above.
These results can be formalized and generalized in the d-separation or Bayes’ ball algorithm. While this algorithm is beyond the scope of this textbook, we’ll look at a variant of it in a few chapters when we talk about causality.