import numpy as np
import pandas as pd
from scipy import stats
from IPython.display import YouTubeVideo
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
Bayesian Inference and Sampling#
In this section, we’ll focus on computing and using posterior distributions in more sophisticated Bayesian models. We’ll start by discussing why posterior distributions are useful in Bayesian inference, and then explain why they’re hard. Then, we’ll learn about approximating distributions using sampling.
Why we need posterior distributions#
In general, we need the posterior distribution so that we can make statements and decisions about our unknown quantity of interest, \(\theta\). We saw that for simple models like the product review model or the model for heights, it was easy to compute the posterior exactly, because we chose a conjugate prior.
In the product review example:
Our parameter of interest \(\theta\) represents the probability of a positive review.
If we chose a Beta prior, i.e., \(\theta \sim \mathrm{Beta}(\alpha, \beta)\), then the posterior distribution also belonged to the Beta family: \(\theta | x \sim \mathrm{Beta}(\alpha + \sum x_i, \beta + n - \sum x_i)\).
This made it easy to determine things like the MAP estimate or LMSE estimate, simply by using known properties of the Beta distribution.
But what if our posterior distribution didn’t have such a convenient form? In that case, we would have to compute the posterior (and any estimates from it) ourselves:
\begin{align} p(\theta|x) &= \frac{p(x|\theta)p(\theta)}{p(x)} \ &= \frac{p(x|\theta)p(\theta)}{\int p(x|\theta)p(\theta),d\theta} \ \end{align}
In general, the integral in the denominator could be impossible to compute. We call the denominator the normalizing constant: it’s a constant because it doesn’t depend on \(\theta\), and it’s normalizing because we need it for the distribution or density to sum or integrate to 1.
In the next section, we’ll see a few examples that illustrate why computing the normalizing constant is hard, but first, let’s look at three examples of why we might need to know it in the first place.
Computing probabilities#
Suppose we want to know the probability that \(\theta\) is greater than 0.7, given the observed data. In this case, we can set up an integral to compute this:
\begin{align} P(\theta > 0.7 | x) &= \int_{0.7}^1 p(\theta|x) , dx \ &= \int_{0.7}^1 \frac{p(x|\theta)p(\theta)}{p(x)} , dx \ &= \frac{1}{p(x)} \int_{0.7}^1 p(x|\theta)p(\theta) , dx \end{align}
In the last step, we used the fact that p(x) doesn’t depend on \(\theta\).
If we don’t know \(p(x)\), then our probability will be off by an unknown factor. For example, suppose the true probability is 0.9, the integral is 0.0009, and \(p(x) = 0.001\). In this case, if we don’t know the normalizing constant, there’s no way we can determine the probability: we’ll always be wrong by an unknown factor, which means that our answer is useless.
MAP Estimation#
Suppose we want to compute the MAP estimate:
In the last step, we used the fact that p(x) doesn’t depend on \(\theta\).
If \(\theta\) is low-dimensional and continuous, we can easily optimize this either analytically or sometimes numerically. If \(\theta\) is discrete and doesn’t take on too many different values, we can search over all possible values. However, if \(\theta\) is discrete and takes on an intractably large number of possible values, then we’d need to search over all of them, which would be impossible.
To summarize: for low-dimensional continuous variables, or discrete random variables with a low number of possible values, we can compute the MAP estimate without needing to know the exact posterior. For higher-dimensional random variables and/or discrete random variables with many possible values, this won’t work.
LMSE Estimation#
Suppose we want to compute the LMSE estimate. Recall the definition of conditional expectation (see Data 140 textbook, Chapter 9 and Chapter 15):
In order to compute the LMSE estimate, we need to compute the denominator, \(p(x)\). If we don’t know it, then our estimate will be off by a multiplicative factor that we don’t know, making it effectively useless.
The same is true for computing the expected value of any other function of \(\theta\), or any other probability involving the posterior distribution. For example, answering the question “according to the posterior distribution, what is the variance of \(\theta\)?” will lead to the same problem.
To summarize: any computations involving the posteriors (probabilities, expectations, etc.) require us to have the full normalized distribution: the numerator in Bayes’ rule isn’t enough.
Why computing posterior distributions is hard#
In simple models like our product review model or our model for heights, it was easy to compute the exact posterior for the unknown variable that we were interested in. This happened because we chose a conjugate prior. In most other cases, computing the exact posterior is hard! Here are two examples:
One-dimensional non-conjugate prior#
Let’s return to the product review example, but this time, instead of a Beta prior, we choose \(p(\theta) = \frac{2}{\pi}\cos\left(\frac{\pi}{2} \theta\right)\) for \(\theta \in [0, 1]\).
This distribution looks much more complicated: we can’t reduce it to a known distribution at all. So, in order to properly compute \(p(\theta|x)\), we’d need to figure out the normalizing constant. This requires solving the integral:
This integral is difficult to solve in closed form. However, since this is a one-dimensional problem, we could take advantage of numerical integration. For a particular sequence of values \(x_1, \ldots, x_n\), we can compute a numerical approximation to the integral, and find the normalizing constant that way. As we saw above, we don’t need the normalizing constant if we’re only interested in the MAP estimate, but we can’t compute the LMSE estimate without it.
Multi-dimensional example#
Consider the exoplanet model from last time: \(x_i\) is the (observed) radius of planet \(i\), \(z_i\) is whether the planet belongs to group 0 (small, possibly habitable planets) or group 1 (large, possibly inhabitable planets), and \(\mu_0\) and \(\mu_1\) are the mean radii of those two groups, respectively.
We can write the likelihood and prior. To simplify, we’ll write \(\mathcal{N}(y; m, s) = \frac{1}{s \sqrt{2\pi}} \exp\left\{-\frac{1}{2s^2}(y - m)^2\right\}\)
We can try computing the posterior over the hidden variables \(z_i\), \(\mu_0\), and \(\mu_1\). We’ll use the notation \(z_{1:n}\) to represent \(z_1, \dots, z_n\) (and similarly for \(x_{1:n}\)).
This distribution is more complicated than anything we’ve seen up until now. It’s the joint distribution over \(n+2\) random variables (the group labels \(z_1, \ldots, z_n\) and the two group means \(\mu_0\) and \(\mu_1\)).
Computing the normalization constant \(p(x_{1:n})\) requires a complicated combination of sums and integrals:
For our dataset of over 500 planets, the sums alone would require a completely intractable amount of computation:
2**517
429049853758163107186368799942587076079339706258956588087153966199096448962353503257659977541340909686081019461967553627320124249982290238285876768194691072
Worse still, we can’t even compute the MAP estimate for the labels \(z_i\): in order to find the one that maximizes the numerator, we’d have to search over all \(2^{517}\) combinations, which is also completely intractable.
Even in this fairly simple model, with two groups, we’ve found that exact inference is completely hopeless: there’s no way we can compute the exact posterior for all our unknowns. In the rest of this notebook, we’ll talk about ways to get around this problem using approximations to the posterior distribution.
Approximation with Samples#
We’ve seen before that we can compute an empirical distribution from a sample of data points. In this section, we’ll use sampling to approximate distributions.
Let’s start by using samples to approximate a known, easy-to-compute distribution: Beta\((3, 4)\).
from scipy import stats
distribution = stats.beta(3, 4)
# Compute the exact PDF:
t = np.linspace(0, 1, 500)
pdf = distribution.pdf(t)
# Draw 1000 samples, and look at the empirical distribution of those samples:
samples = distribution.rvs(1000)
f, ax = plt.subplots(1, 1)
sns.histplot(x=samples, stat='density', bins=20, label='Empirical dist. of samples')
ax.plot(t, pdf, label='Beta(3, 4) pdf')
ax.legend()
<matplotlib.legend.Legend at 0x7f50b49a8fa0>
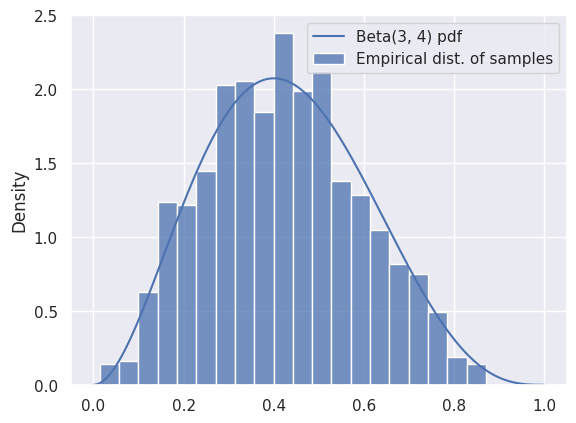
We can see that the samples are a good representation for the distribution, as long as we have enough. We can use the mean of the samples to approximate the mean of the distribution:
# The mean of a Beta(a, b) distribution is a/(a+b):
true_mean = 3 / (3 + 4)
approx_mean = np.mean(samples)
print(true_mean, approx_mean)
0.42857142857142855 0.4194141493007475
Rejection Sampling#
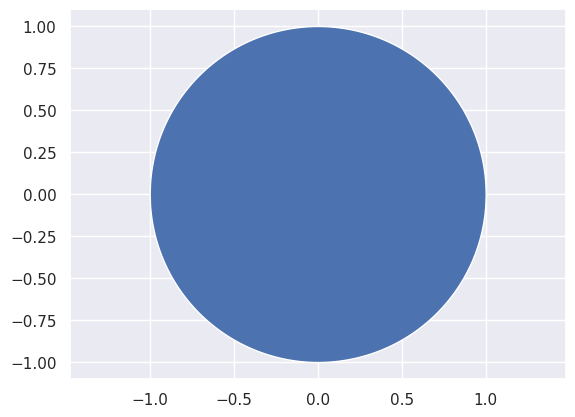
As a warmup, let’s suppose that we want to sample a pair of random variables (\(x_1\), \(x_2\)) drawn uniformly from the unit circle. In other words, we want the uniform distribution over the blue region below:
How can we go about doing this?
(Hint: first sample uniformly over the unit square.)
x_ = np.linspace(-1, 1, 1000)
semicircle = np.sqrt(1-x_**2)
plt.fill_between(x_, -semicircle, semicircle)
plt.axis('equal');
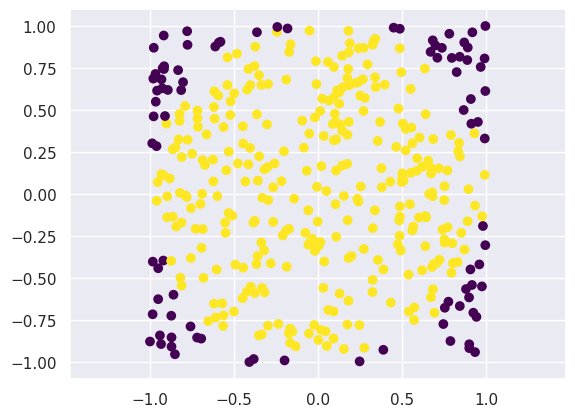
# Number of samples
N = 400
# Samples in the unit square
samples = np.random.uniform(-1, 1, [N, 2])
# Which ones are inside the unit circle?
is_in_circle = (samples[:,0]**2 + samples[:, 1]**2) < 1
plt.figure()
plt.scatter(samples[:, 0], samples[:, 1], c=is_in_circle, cmap='viridis')
plt.axis('equal')
good_samples = samples[is_in_circle]
x1 = good_samples[:, 0]
x2 = good_samples[:, 1]
print('Variance of x1 (estimated from samples): %.3f' % np.var(x1))
Variance of x1 (estimated from samples): 0.259
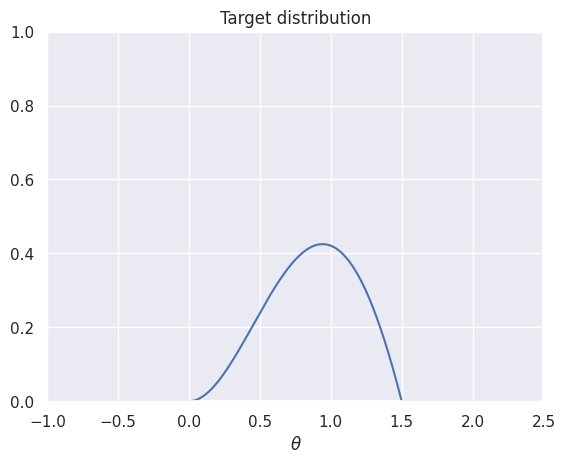
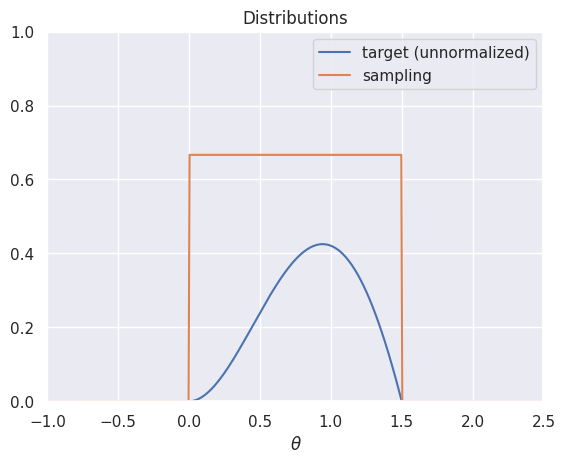
Next, let’s think about sampling from a distribution with a complicated density. Suppose we want to sample from the distribution with density \(p(\theta|x) \propto \theta \cdot (1.5-\theta) \cdot \sin(\theta)\) for \(\theta \in [0,1.5]\):
t = np.linspace(-1, 2.5, 500)
def target(t):
"""The unnormalized distribution we want to sample from"""
return t * (1.5-t) * np.sin(t) * ((t > 0) & (t < 1.5))
plt.plot(t, target(t))
plt.title('Target distribution')
plt.xlabel(r'$\theta$')
plt.axis([-1,2.5,0,1])
plt.show()
How can we make this look like the geometric example from before? We’ll generate samples from a uniform distribution, and throw some away at random (instead of deterministically like in the previous example).
x = np.linspace(-1, 2.5, 500)
def uniform_sampling_dist(t):
"""PDF of distribution we're sampling from: Uniform[0, 1.5]"""
return stats.uniform.pdf(t, 0, 1.5)
plt.plot(t, target(t), label='target (unnormalized)')
plt.plot(t, uniform_sampling_dist(t), label='sampling')
plt.axis([-1,2.5,0,1])
plt.legend()
plt.title('Distributions')
plt.xlabel(r'$\theta$')
plt.show()
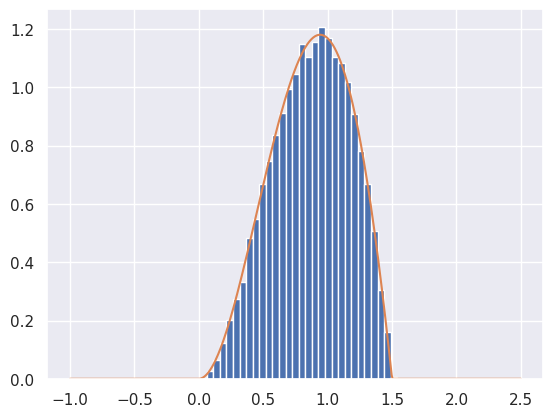
def rejection_sample_uniform(num_samples=100):
# Generate proposals for samples: these are θ-values.
# We'll keep some and reject the rest.
proposals = np.random.uniform(low=0, high=1.5, size=num_samples)
# Acceptance probability is the ratio of the two curves
# These had better all be between 0 and 1!
accept_probs = target(proposals) / uniform_sampling_dist(proposals)
print('Max accept prob: %.3f' % np.max(accept_probs))
# For each sample, we make a decision whether or not to accept.
# Convince yourself that this line makes that decision for each
# sample with prob equal to the value in "accept_probs"!
accept = np.random.uniform(size=num_samples) < accept_probs
num_accept = np.sum(accept)
print('Accepted %d out of %d proposals' % (num_accept, num_samples))
return proposals[accept]
samples = rejection_sample_uniform(num_samples=100000)
# Plot a true histogram (comparable with density functions) using density=True
plt.hist(samples, bins=np.linspace(-0.5, 2, 50), density=True)
# Where did this magic number 0.36 come from? What happens if you change it?
plt.plot(t, target(t) / 0.36)
Max accept prob: 0.638
Accepted 36311 out of 100000 proposals
[<matplotlib.lines.Line2D at 0x7f50b06281c0>]
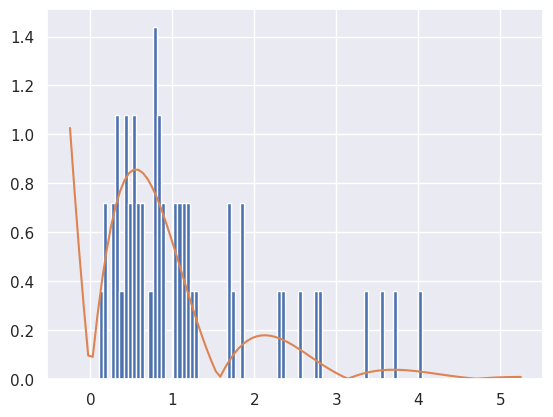
As a final example, what happens if we want to sample across the entire real line? For instance, suppose our density is \(p(\theta|x) \propto \exp(-\theta) |\sin(2\theta)|\) for \(\theta \in [0, \infty)\). We certainly can’t use a uniform proposal distribution, but using the exponential distribution works just fine.
def decaying_target_distribution(t):
"""Unnormalized target distribution as described above"""
return np.exp(-t) * np.abs(np.sin(2*t))
def sampling_distribution_exponential(t):
"""Sampling distribution: exponential distribution"""
# stats.expon has a loc parameter which says how far to shift
# the distribution from its usual starting point of θ=0
return stats.expon.pdf(t, loc=0, scale=1.0)
def rejection_sample_exponential(num_samples=100):
proposals = np.random.exponential(scale=1.0, size=num_samples)
accept_probs = decaying_target_distribution(proposals) / sampling_distribution_exponential(proposals)
accept = np.random.uniform(0, 1, num_samples) < accept_probs
num_accept = np.sum(accept)
print('Accepted %d out of %d proposals' % (num_accept, num_samples))
return proposals[accept]
samples = rejection_sample_exponential(num_samples=100)
plt.hist(samples, bins=np.linspace(0, 5, 100), density=True)
# Find how far the axis goes and draw the unnormalized distribution over it
tmin, tmax, _, _ = plt.axis()
t_inf = np.linspace(tmin, tmax, 100)
# Where did this magic number 0.6 come from? What happens if you change it?
plt.plot(t_inf, decaying_target_distribution(t_inf) / 0.6)
plt.show()
Accepted 56 out of 100 proposals
Markov Chain Monte Carlo#
Coming soon
Markov Chains#
Coming soon
Gibbs sampling#
Coming soon
Implementing models in PyMC#
This section is under development and is subject to change substantially in the next week.
We spent a lot of time doing algebra and computation for the review model. At this point, you might be asking: couldn’t we do a lot of that work computationally? It turns out the answer is yes! PyMC is a Python library for Bayesian inference. You specify a probabilistic model (like the three we’ve just seen), and it will compute the posterior distribution over all unknown variables.
Let’s try it out on the product review model:
We’ll start by specifying our data: Microwave A has 3 positive reviews and 0 negative reviews, and Microwave B has 19 positive reviews and 1 negative review.
reviews_a = np.array([1, 1, 1])
reviews_b = np.append(np.ones(19), np.zeros(1))
import pymc as pm
import arviz as az
# Parameters of the prior
alpha = 1
beta = 5
with pm.Model() as model:
# Define a Beta-distributed random variable called theta
theta = pm.Beta('theta', alpha=alpha, beta=beta)
# Defines a Bernoulli RV called x. Since x is observed, we
# pass in the observed= argument to provide our data
x = pm.Bernoulli('x', p=theta, observed=reviews_b)
# This line asks PyMC to approximate the posterior.
# Don't worry too much about how it works for now.
trace = pm.sample(2000, chains=2, tune=1000, return_inferencedata=True)
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[17], line 1
----> 1 import pymc as pm
2 import arviz as az
4 # Parameters of the prior
ModuleNotFoundError: No module named 'pymc'
trace
-
- chain: 2
- draw: 2000
- chain(chain)int640 1
array([0, 1])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- theta(chain, draw)float640.5836 0.7718 ... 0.6525 0.6525
array([[0.58363117, 0.77177742, 0.68648174, ..., 0.76021834, 0.84907787, 0.84326094], [0.86293833, 0.67042009, 0.67882644, ..., 0.73680676, 0.65252069, 0.65252069]])
- created_at :
- 2023-02-09T19:43:22.340110
- arviz_version :
- 0.11.4
- inference_library :
- pymc3
- inference_library_version :
- 3.11.4
- sampling_time :
- 13.139198064804077
- tuning_steps :
- 1000
<xarray.Dataset> Dimensions: (chain: 2, draw: 2000) Coordinates: * chain (chain) int64 0 1 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999 Data variables: theta (chain, draw) float64 0.5836 0.7718 0.6865 ... 0.7368 0.6525 0.6525 Attributes: created_at: 2023-02-09T19:43:22.340110 arviz_version: 0.11.4 inference_library: pymc3 inference_library_version: 3.11.4 sampling_time: 13.139198064804077 tuning_steps: 1000xarray.Dataset -
- chain: 2
- draw: 2000
- x_dim_0: 20
- chain(chain)int640 1
array([0, 1])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- x_dim_0(x_dim_0)int640 1 2 3 4 5 6 ... 14 15 16 17 18 19
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
- x(chain, draw, x_dim_0)float64-0.5385 -0.5385 ... -0.4269 -1.057
array([[[-0.53848605, -0.53848605, -0.53848605, ..., -0.53848605, -0.53848605, -0.8761838 ], [-0.25905908, -0.25905908, -0.25905908, ..., -0.25905908, -0.25905908, -1.47743391], [-0.37617565, -0.37617565, -0.37617565, ..., -0.37617565, -0.37617565, -1.15989769], ..., [-0.2741496 , -0.2741496 , -0.2741496 , ..., -0.2741496 , -0.2741496 , -1.42802652], [-0.16360438, -0.16360438, -0.16360438, ..., -0.16360438, -0.16360438, -1.89099125], [-0.17047883, -0.17047883, -0.17047883, ..., -0.17047883, -0.17047883, -1.85317289]], [[-0.14741205, -0.14741205, -0.14741205, ..., -0.14741205, -0.14741205, -1.98732432], [-0.39985077, -0.39985077, -0.39985077, ..., -0.39985077, -0.39985077, -1.10993643], [-0.38738979, -0.38738979, -0.38738979, ..., -0.38738979, -0.38738979, -1.13577362], ..., [-0.30542962, -0.30542962, -0.30542962, ..., -0.30542962, -0.30542962, -1.33486676], [-0.42691244, -0.42691244, -0.42691244, ..., -0.42691244, -0.42691244, -1.05705015], [-0.42691244, -0.42691244, -0.42691244, ..., -0.42691244, -0.42691244, -1.05705015]]])
- created_at :
- 2023-02-09T19:43:22.522428
- arviz_version :
- 0.11.4
- inference_library :
- pymc3
- inference_library_version :
- 3.11.4
<xarray.Dataset> Dimensions: (chain: 2, draw: 2000, x_dim_0: 20) Coordinates: * chain (chain) int64 0 1 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999 * x_dim_0 (x_dim_0) int64 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Data variables: x (chain, draw, x_dim_0) float64 -0.5385 -0.5385 ... -0.4269 -1.057 Attributes: created_at: 2023-02-09T19:43:22.522428 arviz_version: 0.11.4 inference_library: pymc3 inference_library_version: 3.11.4xarray.Dataset -
- chain: 2
- draw: 2000
- chain(chain)int640 1
array([0, 1])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- diverging(chain, draw)boolFalse False False ... False False
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) - max_energy_error(chain, draw)float640.6641 -0.8099 ... 0.452 2.478
array([[ 0.66412521, -0.80992875, 0.16758897, ..., -0.42496998, 0.35583789, -0.02404791], [ 0.75810737, -0.26739706, 1.4235164 , ..., -0.62992768, 0.45203004, 2.47789994]]) - acceptance_rate(chain, draw)float640.5147 1.0 0.8457 ... 0.6363 0.1537
array([[0.51472361, 1. , 0.84570137, ..., 0.94810244, 0.85278836, 1. ], [0.55898545, 0.99989903, 0.756212 , ..., 0.92399311, 0.63633505, 0.15369519]]) - perf_counter_start(chain, draw)float649.981 9.982 9.982 ... 12.13 12.13
array([[ 9.98125264, 9.98156231, 9.98200286, ..., 10.84484102, 10.84536025, 10.84581013], [11.35762197, 11.35826779, 11.35886555, ..., 12.12894659, 12.12955231, 12.12992643]]) - energy_error(chain, draw)float640.6641 -0.8099 0.1676 ... 0.452 0.0
array([[ 0.66412521, -0.80992875, 0.16758897, ..., -0.41568721, 0.21579667, -0.02404791], [ 0.53412175, -0.26739706, -0.022043 , ..., -0.62992768, 0.45203004, 0. ]]) - step_size_bar(chain, draw)float641.318 1.318 1.318 ... 1.405 1.405
array([[1.31834025, 1.31834025, 1.31834025, ..., 1.31834025, 1.31834025, 1.31834025], [1.40501964, 1.40501964, 1.40501964, ..., 1.40501964, 1.40501964, 1.40501964]]) - perf_counter_diff(chain, draw)float640.0002024 0.0003317 ... 0.000331
array([[0.00020239, 0.00033167, 0.0003279 , ..., 0.00040403, 0.000352 , 0.00018809], [0.00052456, 0.00049895, 0.00046188, ..., 0.00051428, 0.000283 , 0.00033099]]) - energy(chain, draw)float6414.65 13.63 12.89 ... 13.35 15.01
array([[14.65288797, 13.62794405, 12.88703586, ..., 13.45351496, 13.17883213, 13.11246512], [13.97852996, 13.42988282, 14.52718727, ..., 13.71880621, 13.35017457, 15.01209867]]) - step_size(chain, draw)float641.325 1.325 1.325 ... 1.924 1.924
array([[1.32542105, 1.32542105, 1.32542105, ..., 1.32542105, 1.32542105, 1.32542105], [1.92440441, 1.92440441, 1.92440441, ..., 1.92440441, 1.92440441, 1.92440441]]) - tree_depth(chain, draw)int641 2 2 1 1 2 2 2 ... 2 2 1 1 1 2 1 2
array([[1, 2, 2, ..., 2, 2, 1], [2, 2, 2, ..., 2, 1, 2]]) - lp(chain, draw)float64-14.42 -12.44 ... -13.27 -13.27
array([[-14.41738594, -12.43634721, -12.87346116, ..., -12.44171316, -13.00859721, -12.91917608], [-13.26274899, -13.04719598, -12.95299967, ..., -12.50835506, -13.2711117 , -13.2711117 ]]) - process_time_diff(chain, draw)float640.000203 0.000332 ... 0.00033
array([[0.000203, 0.000332, 0.000327, ..., 0.0004 , 0.000353, 0.000189], [0.000521, 0.000491, 0.000462, ..., 0.000515, 0.000284, 0.00033 ]]) - n_steps(chain, draw)float641.0 3.0 3.0 1.0 ... 1.0 3.0 1.0 3.0
array([[1., 3., 3., ..., 3., 3., 1.], [3., 3., 3., ..., 3., 1., 3.]])
- created_at :
- 2023-02-09T19:43:22.345038
- arviz_version :
- 0.11.4
- inference_library :
- pymc3
- inference_library_version :
- 3.11.4
- sampling_time :
- 13.139198064804077
- tuning_steps :
- 1000
<xarray.Dataset> Dimensions: (chain: 2, draw: 2000) Coordinates: * chain (chain) int64 0 1 * draw (draw) int64 0 1 2 3 4 5 ... 1995 1996 1997 1998 1999 Data variables: (12/13) diverging (chain, draw) bool False False False ... False False max_energy_error (chain, draw) float64 0.6641 -0.8099 ... 0.452 2.478 acceptance_rate (chain, draw) float64 0.5147 1.0 ... 0.6363 0.1537 perf_counter_start (chain, draw) float64 9.981 9.982 9.982 ... 12.13 12.13 energy_error (chain, draw) float64 0.6641 -0.8099 ... 0.452 0.0 step_size_bar (chain, draw) float64 1.318 1.318 1.318 ... 1.405 1.405 ... ... energy (chain, draw) float64 14.65 13.63 12.89 ... 13.35 15.01 step_size (chain, draw) float64 1.325 1.325 1.325 ... 1.924 1.924 tree_depth (chain, draw) int64 1 2 2 1 1 2 2 2 ... 2 2 1 1 1 2 1 2 lp (chain, draw) float64 -14.42 -12.44 ... -13.27 -13.27 process_time_diff (chain, draw) float64 0.000203 0.000332 ... 0.00033 n_steps (chain, draw) float64 1.0 3.0 3.0 1.0 ... 3.0 1.0 3.0 Attributes: created_at: 2023-02-09T19:43:22.345038 arviz_version: 0.11.4 inference_library: pymc3 inference_library_version: 3.11.4 sampling_time: 13.139198064804077 tuning_steps: 1000xarray.Dataset -
- x_dim_0: 20
- x_dim_0(x_dim_0)int640 1 2 3 4 5 6 ... 14 15 16 17 18 19
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
- x(x_dim_0)float641.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 0.0
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0.])
- created_at :
- 2023-02-09T19:43:22.523753
- arviz_version :
- 0.11.4
- inference_library :
- pymc3
- inference_library_version :
- 3.11.4
<xarray.Dataset> Dimensions: (x_dim_0: 20) Coordinates: * x_dim_0 (x_dim_0) int64 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Data variables: x (x_dim_0) float64 1.0 1.0 1.0 1.0 1.0 1.0 ... 1.0 1.0 1.0 1.0 0.0 Attributes: created_at: 2023-02-09T19:43:22.523753 arviz_version: 0.11.4 inference_library: pymc3 inference_library_version: 3.11.4xarray.Dataset
trace.posterior
<xarray.Dataset>
Dimensions: (chain: 2, draw: 2000)
Coordinates:
* chain (chain) int64 0 1
* draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999
Data variables:
theta (chain, draw) float64 0.5836 0.7718 0.6865 ... 0.7368 0.6525 0.6525
Attributes:
created_at: 2023-02-09T19:43:22.340110
arviz_version: 0.11.4
inference_library: pymc3
inference_library_version: 3.11.4
sampling_time: 13.139198064804077
tuning_steps: 1000- chain: 2
- draw: 2000
- chain(chain)int640 1
array([0, 1])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- theta(chain, draw)float640.5836 0.7718 ... 0.6525 0.6525
array([[0.58363117, 0.77177742, 0.68648174, ..., 0.76021834, 0.84907787, 0.84326094], [0.86293833, 0.67042009, 0.67882644, ..., 0.73680676, 0.65252069, 0.65252069]])
- created_at :
- 2023-02-09T19:43:22.340110
- arviz_version :
- 0.11.4
- inference_library :
- pymc3
- inference_library_version :
- 3.11.4
- sampling_time :
- 13.139198064804077
- tuning_steps :
- 1000
plt.hist(trace.posterior['theta'].values.flatten())
(array([ 7., 34., 108., 259., 525., 816., 960., 830., 394., 67.]),
array([0.45975661, 0.5102932 , 0.5608298 , 0.61136639, 0.66190298,
0.71243957, 0.76297616, 0.81351275, 0.86404934, 0.91458593,
0.96512252]),
<BarContainer object of 10 artists>)
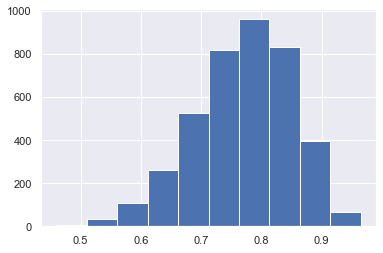
Exoplanet model in PyMC#
planets = pd.read_csv('exoplanets.csv')
planets.shape
(517, 6)
Let’s try a more interesting model: our mixture model for exoplanets:
First, we’ll need a trick called “fancy indexing”. Here’s how it works:
example_zs = np.array([1, 0, 0, 1, 1, 0])
example_mus = np.array([1.3, 10.2])
means = example_mus[example_zs]
means
array([10.2, 1.3, 1.3, 10.2, 10.2, 1.3])
pi = 0.6 # Prior probability of a planet being in the large/uninhabitable group
sigma = 1.5 # SD of likelihood
mu_p = 5 # Mean of prior
sigma_p = 10 # Variance of prior: important to choose a large value here
with pm.Model() as model_exoplanet:
# This defines a Bernoulli random variable called 'z' in our model.
z = pm.Bernoulli('z', p=pi)
# This creates an array of two random variables called 'mu'
# (one for each group), because we used the shape=2 argument
mu = pm.Normal('mu', mu=mu_p, sigma=sigma_p, shape=2)
planet_means = mu[z]
# this is the tricky bit with the indexing: we'll use the "fancy indexing" idea
# from above
x = pm.Normal('x', mu=planet_means, sigma=sigma, observed=planets['radius'])
trace_exoplanet = pm.sample(2000, chains=2, tune=1000, return_inferencedata=True)
Multiprocess sampling (2 chains in 4 jobs)
CompoundStep
>BinaryGibbsMetropolis: [z]
>NUTS: [mu]
Sampling 2 chains for 1_000 tune and 2_000 draw iterations (2_000 + 4_000 draws total) took 15 seconds.
There were 98 divergences after tuning. Increase `target_accept` or reparameterize.
The acceptance probability does not match the target. It is 0.9468856887070264, but should be close to 0.8. Try to increase the number of tuning steps.
There were 115 divergences after tuning. Increase `target_accept` or reparameterize.
The estimated number of effective samples is smaller than 200 for some parameters.
trace_exoplanet.posterior['mu'].values
array([[[ 20.41165621, 9.86123277],
[ 21.36055514, 9.86654287],
[ 19.19448529, 9.86270205],
...,
[ -7.71052359, 9.82387093],
[ 8.17304564, 9.94514827],
[ -6.88110064, 9.83453165]],
[[-13.94087362, 9.77676235],
[-14.84934374, 9.84739705],
[-10.4067851 , 9.87433603],
...,
[ -4.44106853, 9.88909854],
[ 24.72938946, 9.74129422],
[ 28.20174512, 9.74024087]]])