Notebook Cell
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set() # This helps make our plots look nicer
# These make our figures bigger
plt.rcParams['figure.figsize'] = (6, 4.5)
plt.rcParams['figure.dpi'] = 100
Multiple testing and the replication crisis¶
So far, we’ve looked at false positive rate (FPR) and true positive rate (TPR, or power) when evaluating a single hypothesis test. We saw that when using the traditional null hypothesis significance testing (NHST) framework, we choose a p-value threshold, which is our FPR for each test. If we choose a simple alternative hypothesis, we can compute the TPR by looking at the probability of making a discovery under that alternative hypothesis (i.e., the probability that our test statistic is above our decision threshold under that simple alternative hypothesis).
But in many cases, controlling the false positive rate might not be enough to give us the desired level of errors. To help illustrate this, we’ll consider three researchers conducting hypothetical studies of associations between how much margarine people eat and how many books they read in a year:
Researcher Nat conducts one test, looking at a random sample of all individuals in the US.
Researcher Stan conducts fifty tests, looking at fifty random samples, one from each state in the US.
Researcher Colin conducts 3,244 tests, looking at 3,244 random samples, one from each county in the US.
Suppose all three of them use a p-value threshold of 0.05: this means that they should have only a chance of finding false positives. Also, since the premise of the study is somewhat absurd, we can safely assume that in every test, the null hypothesis is true: in other words, there is no correlation between margarine consumption and reading books. If that’s the case, what is the expected number of false positives each one will find?
The number of FPs each researcher finds is a Bernoulli random variable with parameter and depending on the researcher. So, the expected number of false positives is :
Nat’s expected number of false positives is : this is very close to 0.
Stan’s expected number of false positives is : in other words, even though the null hypothesis is true, Stan should expect to have 2-3 states come up as false positives.
Colin’s expected number of false positives is : Colin should expect to have, on average, 162 counties come up as false positives.
These false positives could have serious impacts! Stan’s study, if covered poorly in the news, could result in dramatic headlines like “California and Idaho show strong link between margarine consumption and reading: should elementary schools serve more margarine to improve reading rates?” While this example seems somewhat silly since it’s obvious that the associations are spurious, this happens often when researchers use poor statistical practices.
A -value threshold of 0.05 means that we should expect that when the null hypothesis is true, of the time, we’ll incorrectly make a discovery. This adds up when doing lots of tests.
This issue can often come up when researchers are deciding which associations to test. For example, a researcher might be interested in the effect of Vitamin D supplements on overall health. If an initial analysis of the data returns no results, the researcher might try to see if the effects are different for people of different genders. If that turns up no results, the researcher might think that Vitamin D absorption from the sun depends on melanin in skin, so they might look at the effect for all six different Fitzpatrick skin types. At this point, in what might be a fairly innocuous sequence of tests, the researcher has already conducted 9 different tests, and the probability of making at least one false positive is.
Different approaches to multiple testing¶
We’ve seen that when we conduct multiple hypothesis tests at a fixed -value threshold, we can control the FPR of each test, but we don’t necessarily control the rate of making errors across multiple tests. In order to address this, we’ll define error rates involving all the tests we conduct, and find algorithms that control those error rates. We’ll let be the number of hypothesis tests, and define two error rates:
The family-wise error rate (FWER) is the probability of any one of the tests resulting in a false positive.
The false discovery rate (FDR) is the expected value of the false discovery proportion (FDP) for the tests.
We’ll explore two algorithms that we can apply to the -values obtained from all tests: Bonferroni correction, which controls FWER, and the Benjamini-Hochberg procedure, which controls FDR. Here, “controls” means that we’re guaranteeing that error rate will be below a certain value we choose. Once we describe the algorithms, we’ll discuss the tradeoffs between the two, and how those tradeoffs are related to the inherent properties of the two error rates.
Randomness, FWER, FDR, and FDP¶
Up until now, we’ve focused primarily on the false discovery proportion (FDP). From now on, we’ll look more at the false discovery rate (FDR), so it’s important to understand the distinction between the two. Throughout this section, we’ll take a frequentist approach, and assume that our data are random (and because our decisions are based on our data, they’re random too), and that reality is fixed and unknown.
The FDP is the value that we obtain for any particular dataset: we obtain data, make a series of decisions, and then the false discovery proportion is based on those particular decisions.
The FDR is the expectation of the FDP, where the expectation is taken over the randomness in the data. In other words, the FDR is the average FDP, averaged across all possible datasets (and weighted by how likely each one is).
Similarly, for any particular dataset, we can define the event “at least one false positive happened”. This event either occurs or it doesn’t for any particular series of decisions. The family-wise error rate (FWER) is the probability of this event occurring for any dataset.
In other words, the false discovery proportion is based on any particular dataset, while the false discovery rate is the average FDP across all possible datasets.
Known and Unknown¶
Throughout this section, we’ll discuss FDP, FDR, and FWER as metrics to help us evaluate a decision-making process. But recall that in reality, we only ever observe the data and the decisions we make based on the data: reality is unknown to us. That means that in many real-world scenarios, we can’t actually compute the FDP for any particular series of decisions, because it requires us to know when and when .
So if we can’t actually compute the FDP, why are we analyzing it?
The key is that the FDR (average FDP) provides a way of evaluating an algorithm. We’ll discuss several procedures, and show that on average, they perform well: in other words, if we look at the performance of these procedures averaged over the randomness in the data, we can mathematically show that the FDR or FWER will be below a certain level. For example, we’ll look at a procedure called Bonferroni correction and show that if we use it, our FWER, or probability of making a false positive, will be less than a particular threshold that we get to specify.
This process, of first defining algorithms that operate on the observed data to make decisions, then theoretically evaluating those algorithms using metrics that depend on unknown variables, is something we’ll see over and over throughout this course.
Bonferroni correction¶
Bonferroni correction is a technique for controlling the FWER. In this context, when we use the term “controlling the FWER at level ”, this just means that we want the FWER to be less than or equal to some value that we choose.
The procedure itself is very simple: it says that if we want to guarantee that our FWER for tests will be less than or equal to , then we just need to use a -value threshold of to make a decision for each test. For example, if we want to guarantee an FWER of 0.01 for 500 tests, we should use a -value threshold for each test of .
Let’s show why this formula works. We’ll start by establishing some facts and definitions that we need.
To start, we’ll need to use the union bound, which states that for events , that
Informally, this says that if we add up the independent probabilities of the events occuring, the result will always be greater than or equal to the probability of the union of those events. Intuitively, this is true because when computing the probability of the union, we have to effectively subtract off the overlap between probabilities.
To use the union bound, we’ll define the indicator variables , where is the event that test results in a false positive. The family-wise error rate is the probability that any one of the tests is a false positive: in other words, . We know from the previous section that if we use the same -value threshold for each test, then .
Putting it all together, we have:
If we choose our -value threshold for each test to be equal to (recall that is our desired FWER), then the right-hand side becomes , and we guarantee that our FWER is less than or equal to .
Controlling FDR¶
Why control FDR instead of FWER?¶
Suppose we conduct 1,000,000 tests, and we want to control the FWER at level 0.01. If we use the Bonferroni procedure, our -value threshold will be 10-8: we will only make discoveries if the -values are incredibly small! This is because FWER is a very strict criterion. Controlling FWER means we want the probability of making any false positives in tests to be less than or equal to : this requirement gets harder and harder to satisfy the larger gets. This is why the -value threshold from Bonferroni correction gets smaller as increases.
Controlling FDR, on the other hand, is much more forgiving of a small number of errors. In our example above, controlling FDR at level 0.01 means that out of the discoveries we make, we want or fewer of them to be wrong. This is still a much stricter criterion than just controlling FPR as we saw with naive thresholding, but it’s easier to satisfy as grows without imposing such a drastically low -value threshold. Next, we’ll see an algorithm that strikes this middle ground.
The Benjamini-Hochberg Procedure¶
The Benjamini-Hochberg (often abbreviated to B-H) procedure is slightly more complicated than Bonferroni correction, but it also uses the same -value threshold for all tests. The key is that we use the -values themselves to determine the threshold. Here’s how it works, for a desired FDR :
First, sort the -values, and index them by (i.e., the first one corresponds to , the second one corresponds to , and so on, until the last one corresponds to )
For each sorted -value, compare it to the value (i.e., the smallest p-value gets compared to , the second-smallest gets compared to , and so on, until the largest one gets compared to )
Find the largest sorted -value that’s still below its comparison value
Use that -value as the threshold
A Visual Comparison of Naive thresholding, Bonferroni, and Benjamini-Hochberg¶
Consider the -values we looked at in the last section. We’ll add a column k that provides the index after being sorted:
p_sorted = pd.read_csv('p_values.csv').sort_values('pvalue')
m = len(p_sorted) # number of tests
k = np.arange(1, m+1) # index of each test in sorted order
p_sorted['k'] = k
p_sortedWe can visualize the -values in sorted order:
sns.scatterplot(p_sorted, x='k', y='pvalue', hue='is_alternative');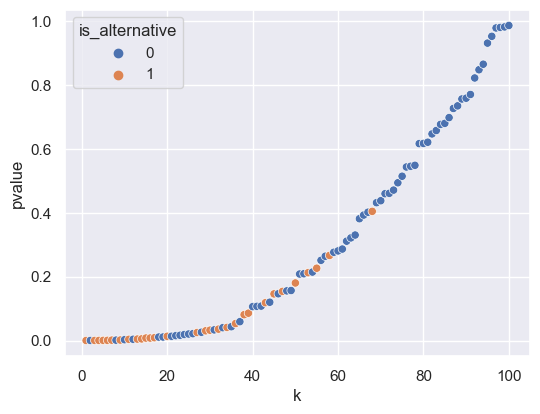
Here, the -axis is , the index, and the -axis represents the -value. We can visualize the results of two techniques:
If we use a naive -value threshold of 0.05 for all tests, we will obtain an FPR of 0.05. This threshold is the black line below.
If we use Bonferroni correction and want a FWER of 0.05 (i.e., the probability of making any false positives at all is 0.05), then we should use a -value threshold of . This threshold is the red dashed line below.
We can see that by using the more conservative Bonferroni threshold (in red), we leave
desired_fwer = 0.05
sns.scatterplot(x=k, y=p_sorted['pvalue'], hue=p_sorted['is_alternative'])
plt.axhline(0.05, label='Naive thresholding', color='black')
plt.axhline(desired_fwer / m, label='Bonferroni', color='tab:red', ls='--')
plt.legend();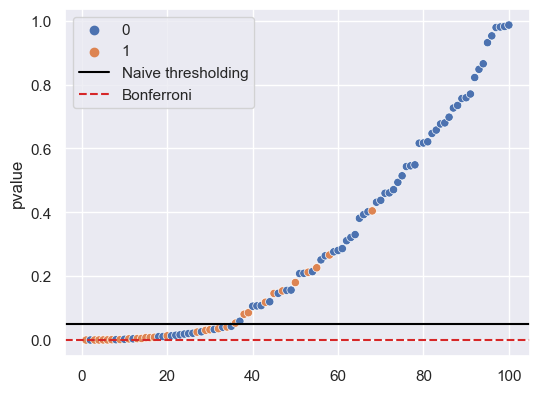
In this visualization, how does the Benjamini-Hochberg procedure work? We compare each -value to the comparison value , which in this visualization is a diagonal line. In order to better see what’s going on, we’ll also zoom in on a narrower range of -values:
desired_fdr = 0.05
sns.scatterplot(x=k, y=p_sorted['pvalue'], hue=p_sorted['is_alternative'])
plt.plot(k, k/m * desired_fdr, label='B-H guide', color='cyan', ls=':')
plt.axis([-0.05, 30, -0.0005, 0.0305])
plt.legend();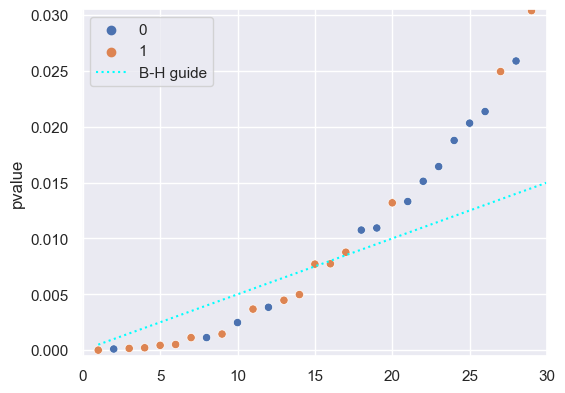
The Benjamini-Hochberg procedure says to take the largest -value that’s below the comparison value : in this case, that’s the point at index 16. This becomes our -value threshold, so we choose to reject the null hypothesis for the first 16 -values (after being sorted). The graph below shows all three thresholds:
desired_fdr = 0.05
desired_fwer = 0.05
# From visually inspecting the graph above, we saw that the 16th
# p-value was the last one below the reference value (cyan line)
bh_threshold = p_sorted.loc[p_sorted['k'] == 16, 'pvalue'].iloc[0]
plt.axhline(
bh_threshold, label=f'B-H threshold (FDR={desired_fdr})', color='tab:green', ls='-.'
)
plt.axhline(
0.05, label='Naive threshold (FPR=0.05)', color='black', ls='-'
)
plt.axhline(
desired_fwer / m, label=f'Bonferroni (FWER={desired_fwer})', color='tab:red', ls='--'
)
sns.scatterplot(x=k, y=p_sorted['pvalue'], hue=p_sorted['is_alternative'])
plt.plot(k, k/m * desired_fdr, label='B-H guide', color='cyan', ls=':')
plt.axis([-0.05, 42.5, -0.001, 0.06])
plt.legend();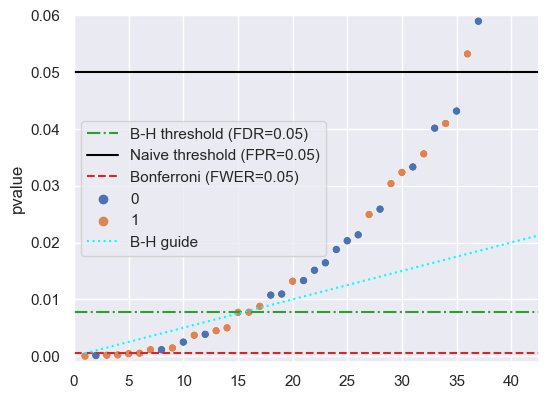
(Optional) Why does Benjamini-Hochberg Control FDR?¶
Text coming soon: see video
Comparing and Contrasting FWER and FDR¶
Now that we’ve seen how we might control FWER and FDR, we’ll build a better understanding of when each one might be better suited for a particular problem. Recall the definitions:
Family-wise error rate (FWER) is the probability that any of the tests is a false positive.
False discovery rate (FDR) is the expected FDP, or equivalently, the expected fraction of discoveries that are incorrect.
Suppose we conduct 1,000,000 tests ().
If we want a FWER of 0.05, this means that we want the probability of any one of the 1,000,000 tests being a false positive to be 0.05 or less. In order to control this probability, we’ll need to be very conservative: after all, even a single false positive will mean that we’ve failed. In other words, controlling FWER requires us to be very conservative, and use very small -value thresholds. This typically leads to very low power, or true positive rate (TPR), because our -value threshold is so low that we miss many true positives.
On the other hand, if we want a FDR of 0.05, this just means that out of the discoveries we make in the 1,000,000 tests, on average, we want or more of them to be correct. We can achieve this with a much less conservative threshold. In other words, when we control FDR, we accept some more false positives, and in return we can achieve a higher true positive rate (i.e., do better in the case where ).
How do these interpretations translate into choosing a rate to control in real-world applications? We’ll look at two examples to help illustrate the difference.
Consider a medical test for a rare condition where the only treatment is a dangerous surgery. In this case, a false positive could subject a patient to unnecessarily undergo the procedure, putting the patient’s life needlessly at risk and potentially inducing medical trauma. A false negative, on the other hand, while still potentially harmful due to lack of treatment, may not be as bad. In this case, or any similar case where a false positive is much worse than a false negative, controlling FWER is likely a better choice, since controlling FWER favors false negatives over false positives.
Consider an online retailer who is interested in conducting many A/B tests to measure whether various website changes improve the chances that shoppers will buy products. In this case, the harm of a false positive is not particularly severe, and we can likely tolerate that of our discoveries could be wrong, especially if it means a better chance of finding changes that increase product purchases.
Note that both of these examples are somewhat ambiguous! In the first example, the cost of a false negative depends strongly on how much the treatment improves the prognosis for patients with the condition, whether follow-on tests exist, and so on. Similarly, in the second example, if the website changes have auxiliary costs (time and money spent by developers to make the changes, changes in user opinion about the website based on the changes, etc.), then this could affect whether we might prefer one over the other.